Mastering Concurrency: A Comprehensive C++ Guide to Processes and Threads
Table of Contents
1. Introduction
First lets begin by defining a piece of system software called the Operating System (OS), which is responsible for orchastrating the sophisticated resource management of a given machine’s hardware as well as providing an abstracted interface for software to be built above.
At the time of me writing this article, I have a web browser open, my spotify playlist on, as well as my VS code editor and a terminal open. Needless to say its practical for a computer to run many programs simultaneously. The crux of this comes down to how can the OS provide an illusion to a single program that its instructions are being executed in an isolated environment by a single processor – to many programs in parallel.
This process of CPU virtualization is implemented in tendem by low level mechanisms with hardware, which perform certain tasks such as a context switch, as well as high level protocols by the OS to make intelligent decisions ex. scheduling policies 1. This makes time sharing of the CPU possible.
2. Why is this important?
Consider the figure below from Karl Rupp which aggregates data from the architecture of Microprocessors since the 1970’s 2.
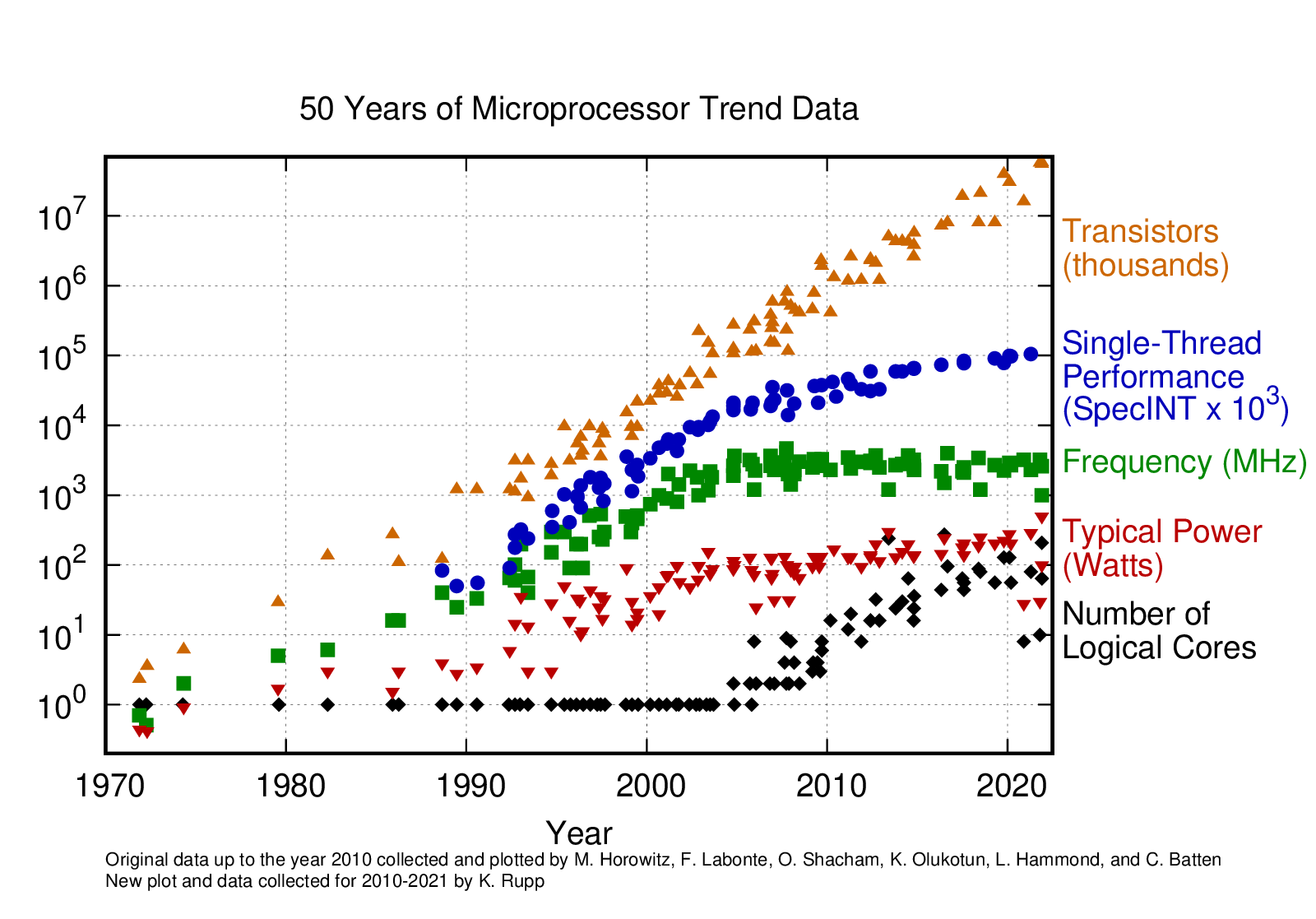
Figure 1. 50 Years of Microprocessor Trend Data (Source: Karl Rupp)
Due to Moore’s Law transistor counts still follow the exponential growth line, however we are at the end of the scaling of clock frequency due to hitting a power ceiling. Therefore, if you want current programs to benefit from future processors, one must make sure to utilize parallel workloads.
2.1. Case for Concurrency
Suppose we are computing the addition between two arrays, then we could speed up the execution of the process considerably by providing one thread to do the work on each array. This parallelization is becoming more and more essential as the landscape of computer architecture has shifted to multi-core designs since the mid 2000’s. Furthermore there exists bottlenecks in our computer programs we can’t get around. Suppose we are fetching data from some server, or reading from disk, or waiting on a message, then we can expect the Input/Output operations are very slow. Therefore we can overlap the waiting with other activities in our program.
3. Explaining Processes
Intuitively you can think of a process as a running program. We write high level human readable code, parse it with sophisticated software into machine code, but it’s still lifeless. It’s merely a stream of instructions waiting to get executed by the computer architecture.
Therefore a process is an abstraction provided by the operating system of a program running with it’s own machine state being executed by one or more threads. Assume for right now we’re working with a single thread.
Two things that make up the machine state are:
-
Address Space: A virtualized memory abstraction which aims to provide protect processes from accessing eachothers memory, illusion of own private space where the OS secretly multiplexing address spaces across physical memory done in an efficient way. Read more from my other post!
- The memory your process is allotted.
- Loaded instructions of the program script
- Run-time stack: any initialized variables, function parameters or return addresses
- Heap: For any explicitely requested dynamic memory allocation (
malloc(),new)
-
Input/Output (IO) Information:
- Unix defaults to having 3 file descriptors (
STDIN,STDOUT,STDERROR) at start
- Unix defaults to having 3 file descriptors (
-
Registers
3.1. Interprocess Communication
Interprocess communication (IPC) are mechanisms the OS provides to allow the processes to manage shared data.
Here are some examples:
- files
- sockets
- signals
- message queue
4. Concurrency
Previously in MultiProgramming we have been able to context switch on a single processor between concurrent processes using a process control block (PCB) to save each processes’ register state.
A thread of execution is the smallest sequence of programmed instructions that can be managed independently by a scheduler
Multi-threaded programs are programs with more than one point of execution i.e many PC’s fetching and executing instructions.
5. Concurrency in C/C++: Pthreads Library
Pthreads are the Standard API for threading specified by ANSI/IEEE POSIX 1003.1-2008. It is a concurrency platform, which is built as a library into your C/C++ programs, which mask the protocols involved in interthread coordination in order to implement the abstraction of a processor 3.
If you wanted to spawn a new thread in your C/C++ program, you could use the <pthread.h> header library and the pthread_create routine.
You only need to pass in two arguments, a buffer variable pthread_t *thread, and a routine pointer void *(*start_routine) (void *). You could additionally pass in the argument list that would be used when the routine is invoked.
Since you just called the pthread_create routine, the pthread_t *thread variable has an updated value indicating the child thread identification integer.
When the invoked routine completes, then the thread pointed by pthread_t variable sends an exit signal pthread_exit (or exit if it’s the last thread in process) signaling it’s done.
It’s typical to call the routine pthread_join on the target thread with another thread in the same process. This could be useful in freeing up shared memory or resources that were allocated previously in the address space.
Now it’s important to maintain some invariance in these critical sections. We want to maintain some truth about the state threads will enter in, and as such they should exit having restored this state if they were to change it.
5.1. Using pthread lock
Of course you can use a higher level abstraction provided in the <pthread.h> library.
The mutex objects are locked by a successful call to pthread_mutex_lock(). Again, if the mutex is already locked by another thread, the calling thread shall be blocked until the mutex becomes available.
5.2. Using pthread conditional variables and signals
The pthread_detach routine marks the target thread as detached. It merely determines the behavior of the system when the thread terminates.
When a detached thread terminates, its resources are automatically released back to the process without the need for another thread to join with the terminated thread.
pthread_cond_wait: Execution of thread containing a lock mutex is self suspended (Not consuming any CPU processing ) until the condition variable cond is signaled.
pthread_cond_signal: A calling thread signals a target thread, which has waited on the condition variable cond, to restart its execution. If many threads are competing on this lock, their order is based on the OS scheduler.
pthread_cond_broadcast: same as above, except restarts all threads.
pthread_exit: Suspends execution of calling thread. This is mostly used in cases where the main thread is only required to spawn threads and leave the threads to do their job.
Additionally process-shared resources (e.g., mutexes, condition variables, semaphores, and file descriptors) are not released.
pthread_join: calling thread will suspend the execution of a target thread.
6. Concurrency Primitives: Semaphore
Semaphore (seh·muh·for) is an abstract variable used to control access from by multiple threads or processes to a critical section. This is a programming primitive used to construct more abstract control structures. First let’s get comfortable with a semaphore.
6.1. Analogy
An analogy for this concept would be to imagine you’re at the gym waiting for a basketball so you can hoop with your buddies. There’s only 6 balls so the sempahore variable would be initialized to 6.
It’s deincremented each time a person comes to the front desk to request a ball, and incremented once returned. When this variable is 0 and a gym goer wishes to consume another ball they are forced to wait until a ball is freed.
It’s important to remember that if you
6.2. Semaphore Semantics
There are only two operations which can change the value of this variable.
In the POSIX standard, these routines exist in the header library <semaphore.h> where sem_t s is a semaphore variable.
sem_post(&s)(up) incrementss. i.e. releases a resource unit.sem_wait(&s)(down) deincrementss: \(S \to S^{\prime}\) . If the updated \(S^{\prime}\) iss < 0then thread is halted untilsis incremented by other process (restored), otherwise proceed forward as intended. i.e. consumes a resource unit.
To keep track of order, a semaphore variable has an associated queue of processes.
We create a sephamore variable sem_init(&s, 0, 0); where __pshared = 0 means we want to share this semaphore variable shared amongst threads in this process only (as opposed to other processes) and __value = 0 means we want it’s initial value to be zero. This is also called a binary semaphore since you could imagine only one thread could hold this resource. If you want a counting semaphore then __value = 5 could work for our analogy example since that would allow 6 threads to check out basketballs.
7. Concurrency Implementation: Mutual Exclusion locks
Suppose you have two competing threads vying for a critical section of code. This could lead to something unwanted called a race condition.
To avoid this we could lock entry into this section by the thread first scheduled by the operating system, then perform work and unlock when finished.
We can achieve a Mutual Exlusion using a binary semaphore.
for (i = 0; i < 10000000; i++) {
sem_wait(&mutex);
counter++;
sem_post(&mutex);
8. Implementing a Producer Consumer
One particular commonly-used pattern in multithreaded programs is the Producer-Consumer (bounded buffer). This involves a parent thread creating \(N\) number of producer threads and \(M\) number of consumer threads that work in tandem like an assembly line processing data in the buffer shared between the two types of threads in conjuction with the lock we just described.
Since we are working with variables whos value will change throughout the program, the sephamores are instantiated in the data segment of the address space (global variables) so that they may be shared amongst all the threads.
Semaphores are also useful to order events in a concurrent program. In ours, a producer should not allocate more data onto the shared buffer if it is at max capacity. Therefore we need to use two variables empty and full to take care of this property. Furthermore to avoid data races, we use a mutex whenever the buffer is tampered with.
sem_t empty;
sem_t full;
sem_t mutex;
Suppose we have a max number of consumer threads we wish to participate in the interaction of this shared buffer, then we initialize max correspondingly with whatever value we wish (probably should be something less than the number of threads your processor supports).
Finally we take advantage of the sem_post(&empty) routine whenever an item is placed and decrement sem_post(&full) when an item is taken out.
sem_init(&full, 0, 0);
sem_init(&empty, 0, max);
sem_init(&mutex, 0, 1);
Heres the two producer, consumer routines shown respectively:
void *producer(void *arg) {
int i;
for (i = 0; i < loops; i++) {
Sem_wait(&empty);
Sem_wait(&mutex);
do_fill(i * 10);
Sem_post(&mutex);
Sem_post(&full);
}
In context of a distributed web application, the server could dispatch many of these consumer threads to process user requests.
void *consumer(void *arg) {
int tmp = 0;
while (tmp != -1) {
Sem_wait(&full);
Sem_wait(&mutex);
tmp = do_get();
Sem_post(&mutex);
Sem_post(&empty);
printf("%lld %d\n", (long long int) arg, tmp);
}
return NULL;
}
8.1. Making a Simple Server Multithreaded
I encourage you to check out the concurrent Gunrock Web Server, built with authentication, transfer, deposit, charge issuance (w. Stripe API integration) endpoints to support client wallet applications, which I contributed to.
Specifically gunrock.cpp serves as the entry point into the program, spins up waiting for requests and uses the same shared buffer scheme described above to process requests in parallel.
9. References
-
R. H. Arpaci-Dusseau and A. C. Arpaci-Dusseau. Operating Systems: Three Easy Pieces. Arpaci-Dusseau Books, 0.80 edition, May 2014 https://pages.cs.wisc.edu/~remzi/OSTEP/. ↩︎
-
Rupp, K. 42 Years of Microprocessor Trend Data February 2018. https://www.karlrupp.net/2018/02/42-years-of-microprocessor-trend-data/ ↩︎
-
Owens, J, MIT 6.172 Lecturers. Multicore Programming, EEC 289Q Performance Engineering of Software Systems. University of California, Davis. October 2021. ↩︎